AUGUSTUS - identifikacija genov#
Avtorja: Kostadin Mitkov, Maša Mencigar
Datum predstavitve: 2022.05.04
Namen vaje#
Namen vaje se je naučiti uporabljati spletni program Augustus, s katerim lahko določimo neznano genomsko zaporedje. Program najde posamezne gene v genomskem zaporedju, identificira pa tudi regije v genu (introni, eksoni, medgenske regije).
Program#
Program: Augustus : gene prediction
Avtorji programa: Prof. Dr. Mario Stanke, Bioinformatics Group of the Institute for Mathematics and Computer Science of the University of Greifswald, http://bioinf.uni-greifswald.de/bioinf/
Reference:
Mario Stanke, Mark Diekhans, Robert Baertsch, David Haussler. (2008) Using native and syntenically mapped cDNA alignments to improve de novo gene finding Bioinformatics 24, Issue 5, 637–644, 10.1093/bioinformatics/btn013
M. Stanke , O. Schöffmann , B. Morgenstern, S. Waack. (2006) Gene prediction in eukaryotes with a generalized hidden Markov model that uses hints from external sources. BMC Bioinformatics 7, 62. 10.1186/1471-2105-7-62
Mario Stanke and Burkhard Morgenstern. (2005) AUGUSTUS: a web server for gene prediction in eukaryotes that allows user-defined constraints Nucleic Acids Research 33, W465-W467. 10.1093/nar/gki458
Mario Stanke and Stephan Waack. (2003) Gene Prediction with a Hidden-Markov Model and a new Intron Submodel Bioinformatics Vol. 19, Suppl. 2,ii215-ii225. 10.1093/bioinformatics/btg1080
Mario Stanke, Rasmus Steinkamp, Stephan Waack and Burkhard Morgenstern. (2004) AUGUSTUS: a web server for gene finding in eukaryotes Nucleic Acids Research Vol. 32, W309-W312 10.1093/nar/gkh379
Opis programa#
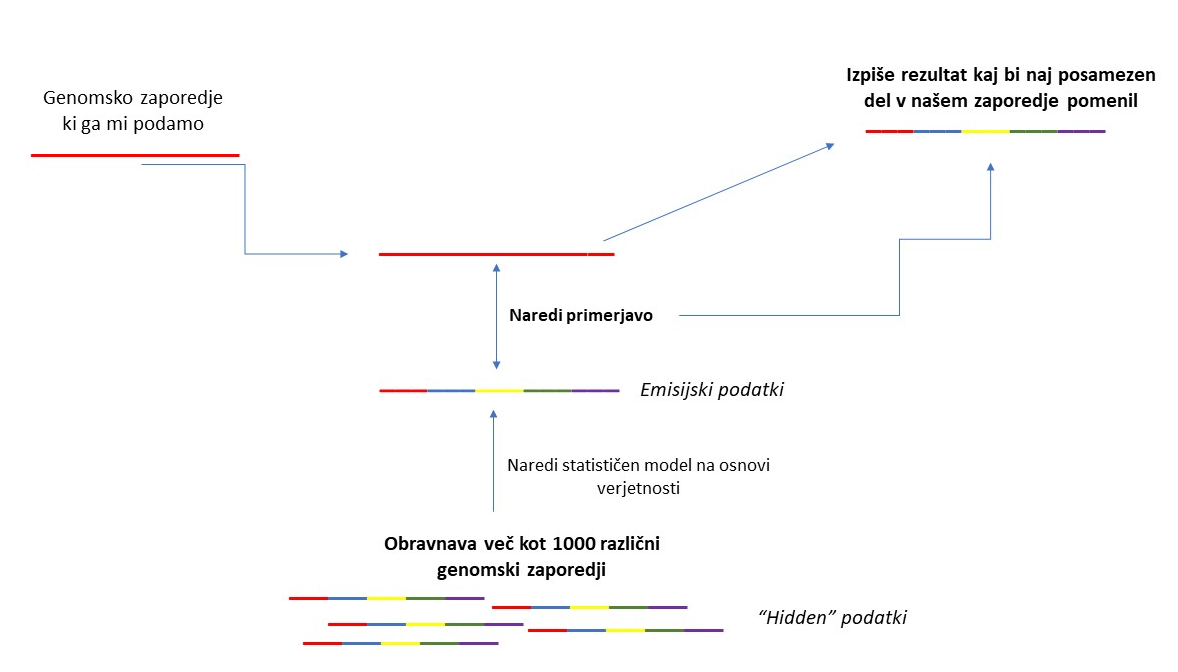
Program deluje na osnovi GHMM (generalized hidden Markov model), ki definira verjetnost porazdelitve za različne dele genomskega zaporedja. Introni, eksoni in medgenske regije ustrezajo stanjem v modelu in vsako stanje ustvari zaporedja DNK z določenimi vnaprej izbranimi emisijskimi verjetnostim. Program najde optimalno razčlenitev danega genomskega zaporedja, to je segmentacija zaporedij v stanja, ki imajo najboljše ujemanje z osnovnim statističnim modelom. Parametri osnovnega statističnega modela so bili določeni z uporabo več kot 1000 različnimi zaporedji z že poznanimi genomskimi zaporedji. Dokazali so da je program Augustus za dolga genomska zaporedja najbolj natančen v primerjavi z drugimi porgrami. Augustus zelo dobro deluje za daljša genomska zaporedja, predvsem za sesalce.
Vhodni podatki#
Genomska zaporedja DNA v FASTA formatu. Maksimalno število baznih parov je 3 milijone.